《智能计算系统》第八章
第八章 智能编程语言
8.1 为什么需要智能编程语言
传统编程语言和智能计算系统存在三方面的鸿沟:一是语义鸿沟,传统编程语言无法高效地描述高层智能计算语义,导致开发智能应用程序效率低下;二是硬件鸿沟,传统编程语言难以高效地抽象智能计算硬件特性,导致最终生成的代码的执行效率较低;三是平台鸿沟,智能计算硬件平台种类繁多并且在不断增长,传统编程语言难以实现跨平台可移植,针对特定平台优化的程序难以实现在不同平台上的高效执行。
8.1.1 语义鸿沟
传统编程语言通常是以面向通用计算的加、减、乘、除等基本标量运算为基础的。而智能计算任务通常核心都是向量和矩阵运算,智能编程语言通过直接提供智能计算核心操作算子,大幅提高开发效率,为了进一步提高开发效率,还出现了面向具体领域的编程语言。
8.1.2 硬件鸿沟
控制逻辑:传统编程语言通过编译优化以及硬件架构优化来充分挖掘代码的并行度,其具体的控制逻辑对用户是透明的,而对于智能计算硬件而言,其指令以高度并行、相对规整的向量指令或宏指令为主。因此传统编程语言中的控制流、大量标量运算,以及相对耗时的片外访存都极容易带来流水线的气泡,影响计算效率。智能编程语言为用户提供更多的底层硬件特性,如特殊的控制流指令让用户直接采用底层硬件所支持的特殊向量或宏指令实现的计算函数来编写程序以降低分支控制的开销;通过提供高层语言特性,让用户更容易控制计算和访存之间的平衡。
存储逻辑:传统通用处理器以硬件管理下对程序员透明的cache为主,辅以程序员可见的逻辑寄存器,传统编程语言并不需要看到上述存储层次,通过编译器优化和硬件架构策略充分利用片上存储缓解存储墙问题。但这种方式无法最大限度地发挥底层硬件的计算性能,智能计算硬件采用程序员显示管理的SPM来降低硬件开销并提高灵活性。
计算逻辑:传统通用处理器主要提高ALU和FPU,一般不具有面向智能计算特性的定制运算单元,如低位宽运算器。而当下很多场景的智能计算任务具有一定的误差容忍度,不需要高精度运算器,故智能计算系统通过提供定制运算单元和更多的数据类型,从而提高效率降低功耗。
8.1.3 平台鸿沟
针对特定硬件平台优化地很好的程序,在新的硬件平台上可移植性存在很大挑战。智能编程语言通过抽取不同硬件平台的共性特征,在硬件抽象层次和性能间寻找最佳平衡点。
8.2 智能计算系统抽象架构
8.2.1 抽象硬件架构
不同规模的计算系统可以整体抽象为存储、控制和计算三大部分。智能计算系统的每一层都包含存储单元、控制单元和若干计算单元。其中每个计算单元又进一步分解为子控制单元、子计算单元和子存储单元三部分。整个系统以这样的方式递归实现。在最底层,每个叶节点都是具体的加速器,用于完成最基本的计算任务。
8.2.2 典型智能计算系统
多卡的DLP服务器可以抽象为五个层次:服务器级(Server)、板卡级(Card)、芯片级(Chip)、处理器簇级(Cluster)和处理器核级(Core)。该架构可以方便地通过增加各层次的规模来提升整个系统算力。
8.2.3 控制模型
指令是实现对计算和存储进行控制的关键。为了设计高效的指令集、需要充分分析智能领域的典型计算模式,提炼最具代表性的操作,并进行针对性设计。
对智能算法进行抽象得到四类典型操作:控制、数据传输、计算(标量、向量和矩阵运算等)和逻辑操作(标量和向量运算等)。
关注计算与存储的交互:尽可能将计算与存储并行,例如可以将控制计 算和访存的指令分开在不同的队列中发射执行,以提高并行度。
8.2.4 计算模型
程序员可见的主要包括定制运算单元和并行计算架构。
8.2.4.1 定制运算单元
智能应用具有一定误差容忍度。因此一般在智能计算系统中会采用定制的低位宽运算单元(如FP16、INT8、 BF16甚至是INT4等)以提升处理能效。由于智能应用的多样性和复杂性,目前对于哪种低位宽最为合适并未形成统一结论。
8.2.4.2 并行计算架构
要求程序员对任务进行切分,将任务尽量均衡地分配到大量并行计算单元上执行。并且需要有相应的同步机制,以保证切分后任务之间的依赖关系。
8.2.5 存储模型
智能应用中存在大量数据密集的内存访问,因此合理地组织存储层次和计算单元同样重要,需要两者协同设计以平衡计算与访存,实现高效的智能计算。存储分为全局存储和本地存储。
8.3 智能编程模型
8.3.1 异构编程模型
异构计算系统组成:(1)通用处理器:控制设备(简称主机端),负责控制和调度等工作。(2)领域处理器:从设备(简称设备端),负责大规模的并行计算或领域专用计算任务。二者协同完成完整计算任务。
异构并行编程模型从用户接口角度大致可分为两类:一是构建全新的异构并行编程语言;二是对现有编程语言进行异构并行扩展。典型异构并行编程模型的对比如下:
| 编程模型 | 类别 | 主要编程考量 |
|---|---|---|
| OpenCL | 语言扩展 | 任务划分+数据分布、通信、同步 |
| CUDA | 语言扩展 | 任务划分+数据分布、通信、同步 |
| Copperhead | 新语言 | 任务划分为主 |
| Merge | 新语言 | 任务划分为主 |
异构编程模型的编译和链接流程如下图所示:
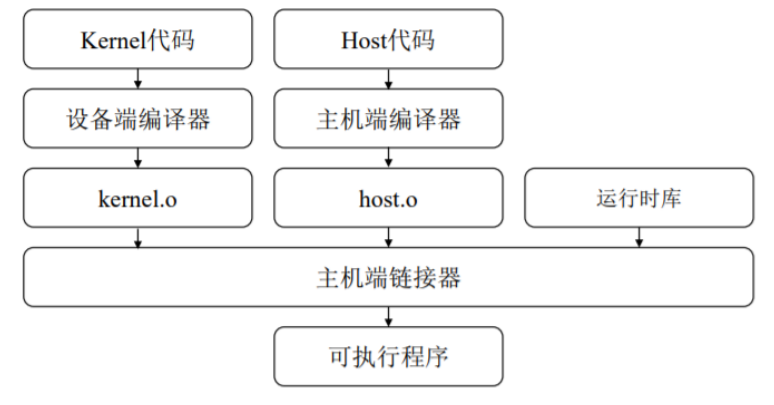
异构并行编程语言编译器需要为任务划分、数据分布、数据通信和同步机制等提供底层支持。具体如下:
(1)任务划分
编程模型需要向程序员提供并行编程接口,方便程序员定义和划分任务。编译器负责底层的任务划分,使得程序可以在并行架构上高效执行。
(2)数据分布
对于编译器和底层运行时系统而言,需要根据算法和硬件架构的特点,通过合适的数据分布指导后续编译和运行时优化。
(3)数据通信
由于设备端通常有多级存储空间、编译器需要支持各种地址空间声明,以方便程序员显式控制存储数据的地址空间。
(4)并行同步
设备端程序一般要求感知多个核的并行处理,因此需要提供对同步机制的支持。
异构运行时的主要任务是保证任务映射及调度,即指定任务具体在哪个设备或计算单元上以何种顺序执行。
8.3.2 通用智能编程模型
8.3.2.1 Kernel函数
Kernel是DLP上执行任务的程序,资源允许情况下DLP可以同时执行多个并行的Kernel。每个Kernel有一个入口函数,BCL中用__dlp_entry__来指定。Kernel的启动需调用运行时API:InvokeKernel函数。设备端程序默认的函数类型:Device函数,以__dlp_device__来修饰。
8.3.2.2 编译器支持
1. 任务划分
用户可以使用内建变量clusterDim,clusterId,coreDim,coreId分别表示Cluster和Core的维度和ID。程序表示任务的内建变量有:taskDim、taskDimX、taskDimY、taskDimZ、taskId、taskIdX、taskIdY、taskIdZ。表示Kernel启动task的规模,有XYZ三个维度,用户根据需求进行指定。
任务调度类型有分为:BLOCK类型(Kernel为单核任务,按单核进行调度)和UNIONx类型(Kernel为多核并行任务,其中x可以为1/2/4,UNION1对应1个cluster4个core)
2. 数据通信
隐式数据管理:在GPR进行标量数据计算,由编译器隐式插入Load/Store指令。
显式数据管理:在DRAM/NRAM/WRAM/SRAM间进行向量及张量数据计算。
3. 同步支持
提供两者不同类型的同步操作:__sync_all(同步任务执行的所有核)和__sync_cluster(同步一个Cluster内部的所有核)。
4. 内建运算
为用户编程提供支持,通用智能编程语言提供并实现了__conv和__mlp等内建函数接口,分别对应卷积和全连接等典型神经网络运算,提高开发效率。
8.3.2.3 运行时支持
智能编程模型采用粗粒度的调度策略:以BLOCK/UNIONx为任务调度单位将Kernel中的任务在时间或空间维度展开。BLOCK(单核调度,当有一个核空闲时,调度一个任务执行)、UNION1(调度时需要1个cluster,当有1个cluster空闲时,调度任务执行)、UNION2(调度时需要2个cluster,当有2个cluster空闲时,调度任务执行)。调度单位需要用户指定,运行时只有当空闲硬件资源数大于调度单位时,Kernel才会被调度。
在智能编程模型中,将执行流的概念抽象为执行队列。队列管理需要执行的任务,队列既可以单独工作,也可以协同工作。
8.4 智能编程语言基础
8.4.1 语法概述
智能编程语言基于过程式语言,主要原因有二:一是当前大多数语言都是过程式的,可以减少用户学习成本;二是当前主流智能算法可以描述为明确的过程,适合采用过程式语言描述。与经典过程式语言一样,智能编程语言同样具有数据和函数两个基本要素。
8.4.2 数据类型
| 基本数据类型 | 长度 | 说明 |
|---|---|---|
| int8_t | 1 byte | 1 字节整数 |
| uint8_t | 1 byte | 1 字节无符号整数 |
| int16_t | 2 byte | 2 字节整数 |
| uint16_t | 2 byte | 2 字节无符号整数 |
| int32_t | 4 byte | 4 字节整数 |
| uint32_t | 4 byte | 4 字节无符号整数 |
| half | 2 byte | 半精度浮点数据类型,采用IEEE-754 fp16格式 |
| float | 4 byte | IEEE-754 fp32格式浮点类型,目前仅支持类型转换计算 |
| char | 1 byte | 对应C语言char类型 |
| bool | 1 byte | 对应C语言bool类型 |
| 指针 | 8 byte | 指针类型 |
8.4.3 宏、常量与内置变量
宏/常量由用户定义,内置变量是语言自带的。宏不仅可以定义常量数据,也可定义一段代码;常量是不可修改的数据,只能在初始化时被赋值。内置变量是编程语言本身包含的常量和变量,不需用户定义即可直接使用。
8.4.4 I/O操作语句
不同层次的智能处理节点有各自的本地存储,需要提供不同存储层次间的数据搬移。常用数据搬移操作类型如下:
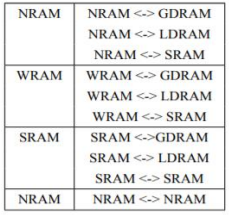
针对上述搬移操作类型,可以在智能编程语言中定义相应的内建函数__memcpy,方便用户进行不同类型的数据搬移。
8.4.5 标量计算语句
两种形式:运算符号(如 +,-,* ,/等)和内建函数(如 abs,max,min 等)。
8.4.6 张量计算语句
张量计算是智能编程语言的主要特点,可以通过内建函数直 接映射到张量计算单元。常见张量计算语句示例如下:
| 张量计算语句 | 具体功能 |
|---|---|
| __vec_add(float* out, float* in1, float* in2, int size) | 向量对位加 |
| __vec_sub(float* out, float* in1, float* in2, int size) | 向量对位减 |
| __vec_mul(float* out, float* in1, float* in2, int size) | 向量对位乘 |
| __conv(half* out, int8* in, int8* weight, half bias, int ci, int hi, int wi, int co, int kh, int kw, int sh, int sw) | 卷积运算 |
| __mlp(half* out, int8* in, int8* weight, half* bias, int ci, int co) | 全连接运算 |
| __maxpool(half* out, half* in, int ci, int hi, int wi, int kh, int kw, int sh, int sw) | 最大池化运算 |
8.4.7 控制流语句
同通用编程语言类似。
8.5 智能应用编程接口
8.5.1 Kernel函数接口
为了充分利用并行资源,需要在Kernel内部对任务进行有效切分,同时在主机端配置和调用相应的Kernel函数接口。
8.5.2 运行时接口
主要包括设备管理、队列管理和内存管理等接口。 设备管理主要涉及初始化、设备设置、设备销毁等操作;队列管理用于管理任务队列;内存管理主要分为主机端内存管理、设备端内存管理和主机与设备端内存拷贝三类。
8.6 智能应用功能调试
编程语言功能调试接口:打印函数接口和例外报错(断言机制和核心转储功能)
编程框架功能调试接口:框架应用层的断言和打印机制、框架核心层的日志打印宏和框架适配层的目标架构调试。
8.7 智能应用性能调优
性能调优的核心是核心是如何充分利用大规模的并行计算单元。常用性能调优方法有:使用片上存储、张量计算(将大量标量运算合并为张量计算)和多核运行(将一个任务分拆到多个核上并行计算)。性能调优接口有:通知接口(找到耗时长的部分)和硬件性能计数器接口(分析硬件执行特征)。也可以使用性能调优工具,具体有:应用级性能剖析工具和系统级性能监控工具。