Java IO流 java io流知识体系(引用自pdai )
Java.io 包几乎包含了所有操作输入、输出需要的类。所有这些流类代表了输入源和输出目标。
Java.io 包中的流支持很多种格式,比如:基本类型、对象、本地化字符集等等。
一个流可以理解为一个数据的序列。输入流表示从一个源读取数据,输出流表示向一个目标写数据。
Java IO流的所有实现类都是从以下四个抽象类基类派生的:
InputStream/Reader:所有的输入流的基类,InputStream是字节输入流,Reader是字符输入流。OutputStream/Writer:所有输出流的基类,OutputStream是字节输出流,Writer是字符输出流。
IO分类-从传输方式上 字节流和字符流的区别 字节流读取单个字节,字符流读取单个字符(一个字节会因为编码不同,所占用的字节也不用)
字节流用来处理二进制文件,比如图片,视频等;字符流用来处理文本文件(一般指人可以阅读的)
字节转字符 字符编码就是将字符转换为字节,而字节解码就是将字节转换为字符。
GBK 编码中,中文字符占 2 个字节,英文字符占 1 个字节;
UTF-8 编码中,中文字符占 3 个字节,英文字符占 1 个字节;
UTF-16be(Big Endian,大端) 编码中,中文字符和英文字符都占 2 个字节。
IO分类-从数据操作上 从数据来源或者说是操作对象角度看,IO类可以分为:
文件(file) FileInputStream、FileOutputStream、FileReader、FileWriter
数组([])
字节数组(byte[]): ByteArrayInputStream、ByteArrayOutputStream
字符数组(char[]): CharArrayReader、CharArrayWriter
管道操作 PipedInputStream、PipedOutputStream、PipedReader、PipedWriter
基本数据类型 DataInputStream、DataOutputStream
缓冲操作 BufferedInputStream、BufferedOutputStream、BufferedReader、BufferedWriter
打印 PrintStream、PrintWriter
对象序列化反序列化 ObjectInputStream、ObjectOutputStream
转换 InputStreamReader、OutputStreamWriter
设计模式 Java IO使用了装饰者模式
装饰者(Decorator)和具体组件(一般是传统继承实现)都继承自同一个组件(Component),具体组件的方法实现不需要依赖于其他的对象,而装饰者则是组合了一个组件,这样它可以被用来装饰其他的装饰者或者具体组件,从而可以动态扩展被装饰者的功能。装饰者的方法有一部分是自己的,这是它独有的功能,并且它可以调用被装饰者的功能(也就是保留了被装饰者的功能)。因此,具体组件应当是装饰层次的最外层,因为只有具体组件的方法实现不需要依赖于其它对象。
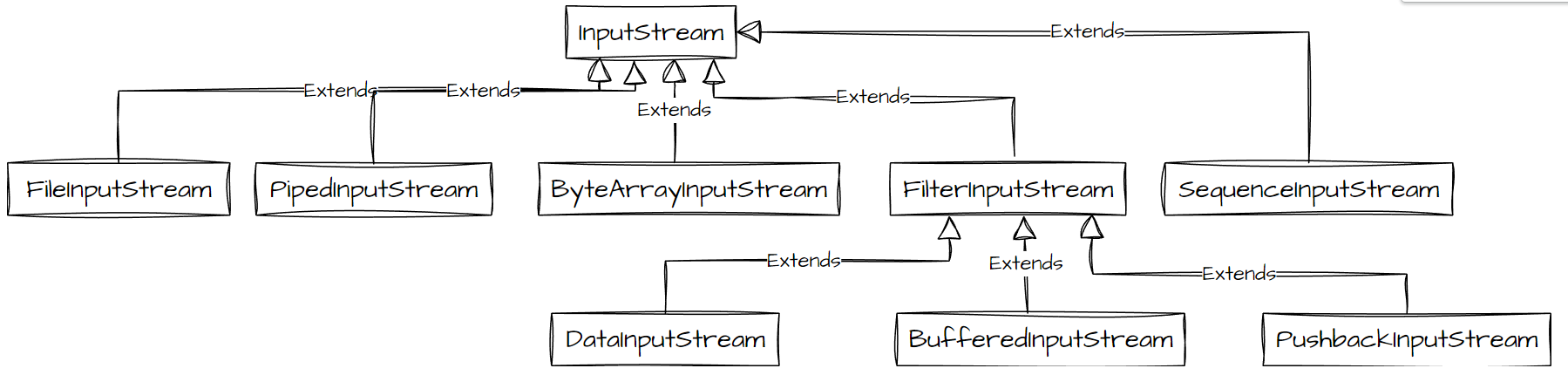
InputStream就采用了装饰者模式:
InputStream 是抽象组件;
FileInputStream 是 InputStream 的子类,属于具体组件,提供了字节流的输入操作;
FilterInputStream 属于抽象装饰者,装饰者用于装饰组件,为组件提供额外的功能。例如 BufferedInputStream 为 FileInputStream 提供缓存的功能。
实例化一个具有缓存功能的字节流对象时,只需要在 FileInputStream 对象上再套一层 BufferedInputStream 对象即可。
1 2 FileInputStream fileInputStream = new FileInputStream (filePath);BufferedInputStream bufferedInputStream = new BufferedInputStream (fileInputStream);
DataInputStream 装饰者提供了对更多数据类型进行输入的操作,比如 int、double 等基本类型。
InputStream类重要方法设计如下:
Java读取字节流的read方法一次读一个byte返回int的原因:
读取二进制数据按字节读取,每次读一个字节(byte)。read()的底层是由C++实现的(native函数),返回的是unsigned byte,取值范围为[0~255],但在java中没有对应的类型,所以只能用int类型接收,由Java接收转为int,范围为[0,255]。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public abstract int read () public int read (byte b[]) public int read (byte b[], int off, int len) public byte [] readAllBytes()public byte [] readNBytes(int len)public int readNBytes (byte [] b, int off, int len) public long skip (long n) public int available () public void close () public synchronized void mark (int readlimit) public synchronized void reset () public boolean markSupported () public long transferTo (OutputStream out)
其抽象类源码如下:
JDK9的更新点
类 java.io.InputStream 中增加了新的方法来读取和复制 InputStream 中包含的数据。
readAllBytes:读取 InputStream 中的所有剩余字节。readNBytes: 从 InputStream 中读取指定数量的字节到数组中。transferTo:读取 InputStream 中的全部字节并写入到指定的 OutputStream 中 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 public abstract class InputStream implements Closeable { private static final int MAX_SKIP_BUFFER_SIZE = 2048 ; private static final int DEFAULT_BUFFER_SIZE = 8192 ; public static InputStream nullInputStream () { return new InputStream () { private volatile boolean closed; private void ensureOpen () throws IOException { if (closed) { throw new IOException ("Stream closed" ); } } @Override public int available () throws IOException { ensureOpen(); return 0 ; } @Override public int read () throws IOException { ensureOpen(); return -1 ; } @Override public int read (byte [] b, int off, int len) throws IOException { Objects.checkFromIndexSize(off, len, b.length); if (len == 0 ) { return 0 ; } ensureOpen(); return -1 ; } @Override public byte [] readAllBytes() throws IOException { ensureOpen(); return new byte [0 ]; } @Override public int readNBytes (byte [] b, int off, int len) throws IOException { Objects.checkFromIndexSize(off, len, b.length); ensureOpen(); return 0 ; } @Override public byte [] readNBytes(int len) throws IOException { if (len < 0 ) { throw new IllegalArgumentException ("len < 0" ); } ensureOpen(); return new byte [0 ]; } @Override public long skip (long n) throws IOException { ensureOpen(); return 0L ; } @Override public long transferTo (OutputStream out) throws IOException { Objects.requireNonNull(out); ensureOpen(); return 0L ; } @Override public void close () throws IOException { closed = true ; } }; } public abstract int read () throws IOException; public int read (byte b[]) throws IOException { return read(b, 0 , b.length); } public int read (byte b[], int off, int len) throws IOException { Objects.checkFromIndexSize(off, len, b.length); if (len == 0 ) { return 0 ; } int c = read(); if (c == -1 ) { return -1 ; } b[off] = (byte )c; int i = 1 ; try { for (; i < len ; i++) { c = read(); if (c == -1 ) { break ; } b[off + i] = (byte )c; } } catch (IOException ee) { } return i; } private static final int MAX_BUFFER_SIZE = Integer.MAX_VALUE - 8 ; public byte [] readAllBytes() throws IOException { return readNBytes(Integer.MAX_VALUE); } public byte [] readNBytes(int len) throws IOException { if (len < 0 ) { throw new IllegalArgumentException ("len < 0" ); } List<byte []> bufs = null ; byte [] result = null ; int total = 0 ; int remaining = len; int n; do { byte [] buf = new byte [Math.min(remaining, DEFAULT_BUFFER_SIZE)]; int nread = 0 ; while ((n = read(buf, nread, Math.min(buf.length - nread, remaining))) > 0 ) { nread += n; remaining -= n; } if (nread > 0 ) { if (MAX_BUFFER_SIZE - total < nread) { throw new OutOfMemoryError ("Required array size too large" ); } total += nread; if (result == null ) { result = buf; } else { if (bufs == null ) { bufs = new ArrayList <>(); bufs.add(result); } bufs.add(buf); } } } while (n >= 0 && remaining > 0 ); if (bufs == null ) { if (result == null ) { return new byte [0 ]; } return result.length == total ? result : Arrays.copyOf(result, total); } result = new byte [total]; int offset = 0 ; remaining = total; for (byte [] b : bufs) { int count = Math.min(b.length, remaining); System.arraycopy(b, 0 , result, offset, count); offset += count; remaining -= count; } return result; } public int readNBytes (byte [] b, int off, int len) throws IOException { Objects.checkFromIndexSize(off, len, b.length); int n = 0 ; while (n < len) { int count = read(b, off + n, len - n); if (count < 0 ) break ; n += count; } return n; } public long skip (long n) throws IOException { long remaining = n; int nr; if (n <= 0 ) { return 0 ; } int size = (int )Math.min(MAX_SKIP_BUFFER_SIZE, remaining); byte [] skipBuffer = new byte [size]; while (remaining > 0 ) { nr = read(skipBuffer, 0 , (int )Math.min(size, remaining)); if (nr < 0 ) { break ; } remaining -= nr; } return n - remaining; } public int available () throws IOException { return 0 ; } public void close () throws IOException {} public synchronized void mark (int readlimit) {} public synchronized void reset () throws IOException { throw new IOException ("mark/reset not supported" ); } public boolean markSupported () { return false ; } public long transferTo (OutputStream out) throws IOException { Objects.requireNonNull(out, "out" ); long transferred = 0 ; byte [] buffer = new byte [DEFAULT_BUFFER_SIZE]; int read; while ((read = this .read(buffer, 0 , DEFAULT_BUFFER_SIZE)) >= 0 ) { out.write(buffer, 0 , read); transferred += read; } return transferred; }
JDK11为什么会增加nullInputStream方法的设计?(空对象模式)
在空对象模式(Null Object Pattern)中,一个空对象取代 NULL 对象实例的检查。Null 对象不是检查空值,而是反应一个不做任何动作的关系。这样的 Null 对象也可以在数据不可用的时候提供默认的行为。
在空对象模式中,创建一个指定各种要执行的操作的抽象类和扩展该类的实体类,还创建一个未对该类做任何实现的空对象类,该空对象类将无缝地使用在需要检查空值的地方。
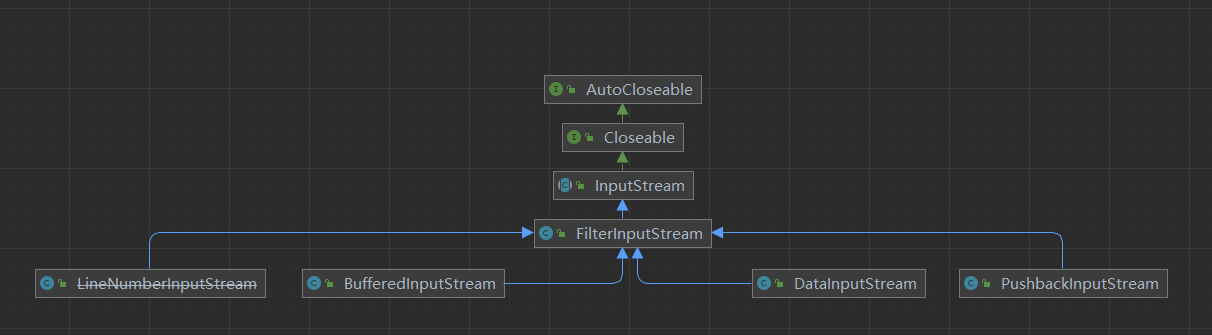
FilterInputStream是InputStream特殊的子类,其是装饰者模式的应用。
在FilterStream类中,有如下field:
1 protected volatile InputStream in;
这使得FilterInputStream可以在InputStream基础上,能够更灵活的,动态地扩展其它功能,而不需要修改任何现有的底层代码。
并且这个域在构造方法中传入:
1 2 3 protected FilterInputStream (InputStream in) { this .in = in; }
并且其read方法直接调用了InputStream类中的read方法:
1 2 3 public int read () throws IOException { return in.read(); }
FilterInputStream作为装饰者类,其子类如下:
数据输入流允许应用程序以独立于机器的方式从底层输入流中直接读取原始 Java 数据类型。应用程序使用数据输出流来写入稍后可以由数据输入流读取的数据。
其成员方法如下:
以readInt()方法为例,以下是其源码:
因为Java中int类型四个字节,故连续读入四个字节,并且进行各自位置上的移位操作,最后相加成为int返回
1 2 3 4 5 6 7 8 9 public final int readInt () throws IOException { int ch1 = in.read(); int ch2 = in.read(); int ch3 = in.read(); int ch4 = in.read(); if ((ch1 | ch2 | ch3 | ch4) < 0 ) throw new EOFException (); return ((ch1 << 24 ) + (ch2 << 16 ) + (ch3 << 8 ) + (ch4 << 0 )); }
BufferedInputStream维护一个8192字节 的内部缓冲区。在BufferedInputStream中进行读取操作期间,会从磁盘读取一部分字节并将其存储在内部缓冲区中。并从内部缓冲区中逐个读取字节。因此,减少了与磁盘的通信次数。因此使用BufferedInputStream读取字节更快。
其类图如下:
其部分源码如下:
每次调用read读取数据时,先查看要读取的数据是否在缓存中,如果在缓存中,直接从缓存中读取;如果不在缓存中,则调用fill方法,从InputStream中读取一定的存储到buffer中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 private void fill () throws IOException { byte [] buffer = getBufIfOpen(); if (markpos < 0 ) pos = 0 ; else if (pos >= buffer.length) if (markpos > 0 ) { int sz = pos - markpos; System.arraycopy(buffer, markpos, buffer, 0 , sz); pos = sz; markpos = 0 ; } else if (buffer.length >= marklimit) { markpos = -1 ; pos = 0 ; } else if (buffer.length >= MAX_BUFFER_SIZE) { throw new OutOfMemoryError ("Required array size too large" ); } else { int nsz = (pos <= MAX_BUFFER_SIZE - pos) ? pos * 2 : MAX_BUFFER_SIZE; if (nsz > marklimit) nsz = marklimit; byte nbuf[] = new byte [nsz]; System.arraycopy(buffer, 0 , nbuf, 0 , pos); if (!bufUpdater.compareAndSet(this , buffer, nbuf)) { throw new IOException ("Stream closed" ); } buffer = nbuf; } count = pos; int n = getInIfOpen().read(buffer, pos, buffer.length - pos); if (n > 0 ) count = n + pos; } public synchronized int read () throws IOException { if (pos >= count) { fill(); if (pos >= count) return -1 ; } return getBufIfOpen()[pos++] & 0xff ; }
OutputStream类源码实现 OutputStream类实现关系
OutputStream抽象类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 public abstract void write (int b) public void write (byte b[]) public void write (byte b[], int off, int len) public void flush () public void close ()
常见IO类使用 File相关 File 类可以用于表示文件和目录的信息,但是它不表示文件的内容。例如递归地列出一个目录下所有文件:
1 2 3 4 5 6 7 8 9 10 11 12 public static void listAllFiles (File dir) { if (dir == null || !dir.exists()) { return ; } if (dir.isFile()) { System.out.println(dir.getName()); return ; } for (File file : dir.listFiles()) { listAllFiles(file); } }
字节流相关 1 2 3 4 5 6 7 8 9 10 11 12 13 public static void copyFile (String src, String dist) throws IOException { FileInputStream in = new FileInputStream (src); FileOutputStream out = new FileOutputStream (dist); byte [] buffer = new byte [20 * 1024 ]; while (in.read(buffer, 0 , buffer.length) != -1 ) { out.write(buffer); } in.close(); out.close(); }
实现逐行输出文本文件的内容 1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static void readFileContent (String filePath) throws IOException { FileReader fileReader = new FileReader (filePath); BufferedReader bufferedReader = new BufferedReader (fileReader); String line; while ((line = bufferedReader.readLine()) != null ) { System.out.println(line); } bufferedReader.close(); }
Java 中的网络支持
InetAddress: 用于表示网络上的硬件资源,即 IP 地址;
URL: 统一资源定位符;
Sockets: 使用 TCP 协议实现网络通信;
Datagram: 使用 UDP 协议实现网络通信。
InetAddress
没有公有的构造函数,只能通过静态方法来创建实例。
1 2 InetAddress.getByName(String host); InetAddress.getByAddress(byte [] address);
URL
可以直接从 URL 中读取字节流数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static void main (String[] args) throws IOException { URL url = new URL ("http://www.baidu.com" ); InputStream is = url.openStream(); InputStreamReader isr = new InputStreamReader (is, "utf-8" ); BufferedReader br = new BufferedReader (isr); String line; while ((line = br.readLine()) != null ) { System.out.println(line); } br.close(); }
Sockets
ServerSocket: 服务器端类
Socket: 客户端类
服务器和客户端通过 InputStream 和 OutputStream 进行输入输出。
Datagram
DatagramSocket: 通信类
DatagramPacket: 数据包类